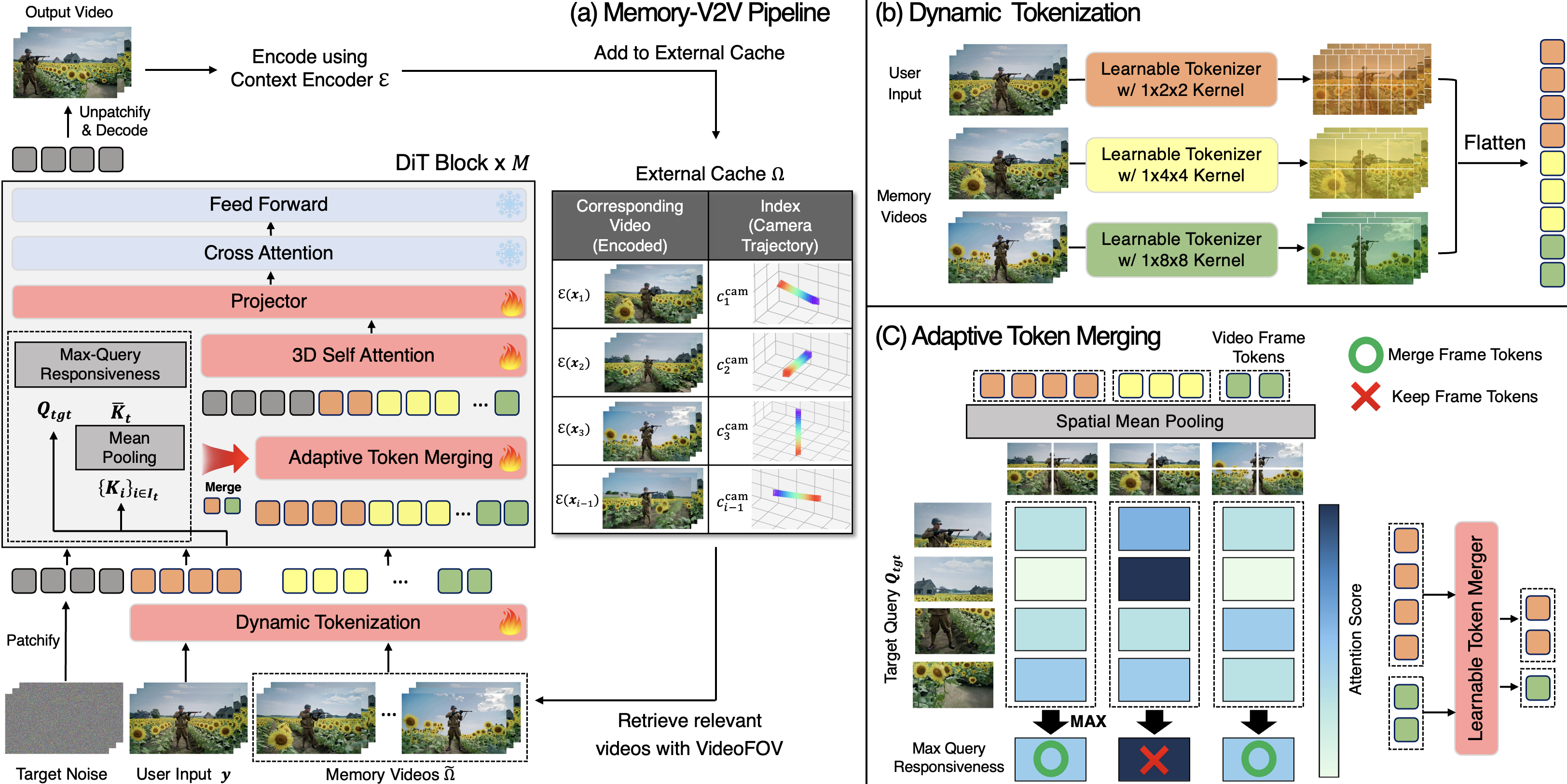
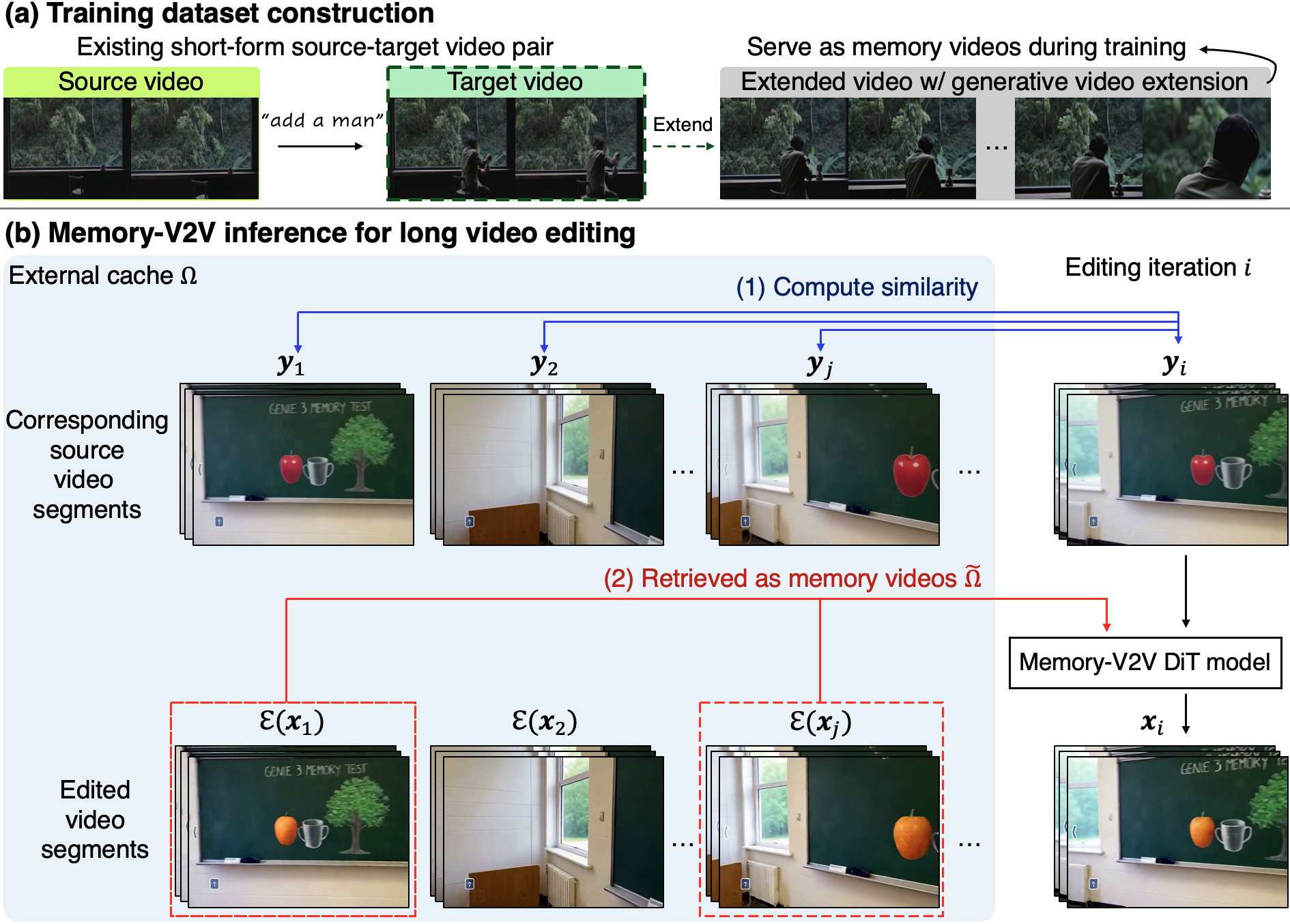
Baseline Comparisons
We compare Memory-V2V against state-of-the-art video-to-video diffusion frameworks, including TrajectoryCrafter[1] and ReCamMaster[2] for video novel view synthesis, and TokenFlow[3], RAVE[4], CCEdit[5], LucyEdit[6] and the FIFO[7]-enhanced variant of LucyEdit for text-guiided long-video editing.
(a) Multi-turn Video Novel View Synthesis
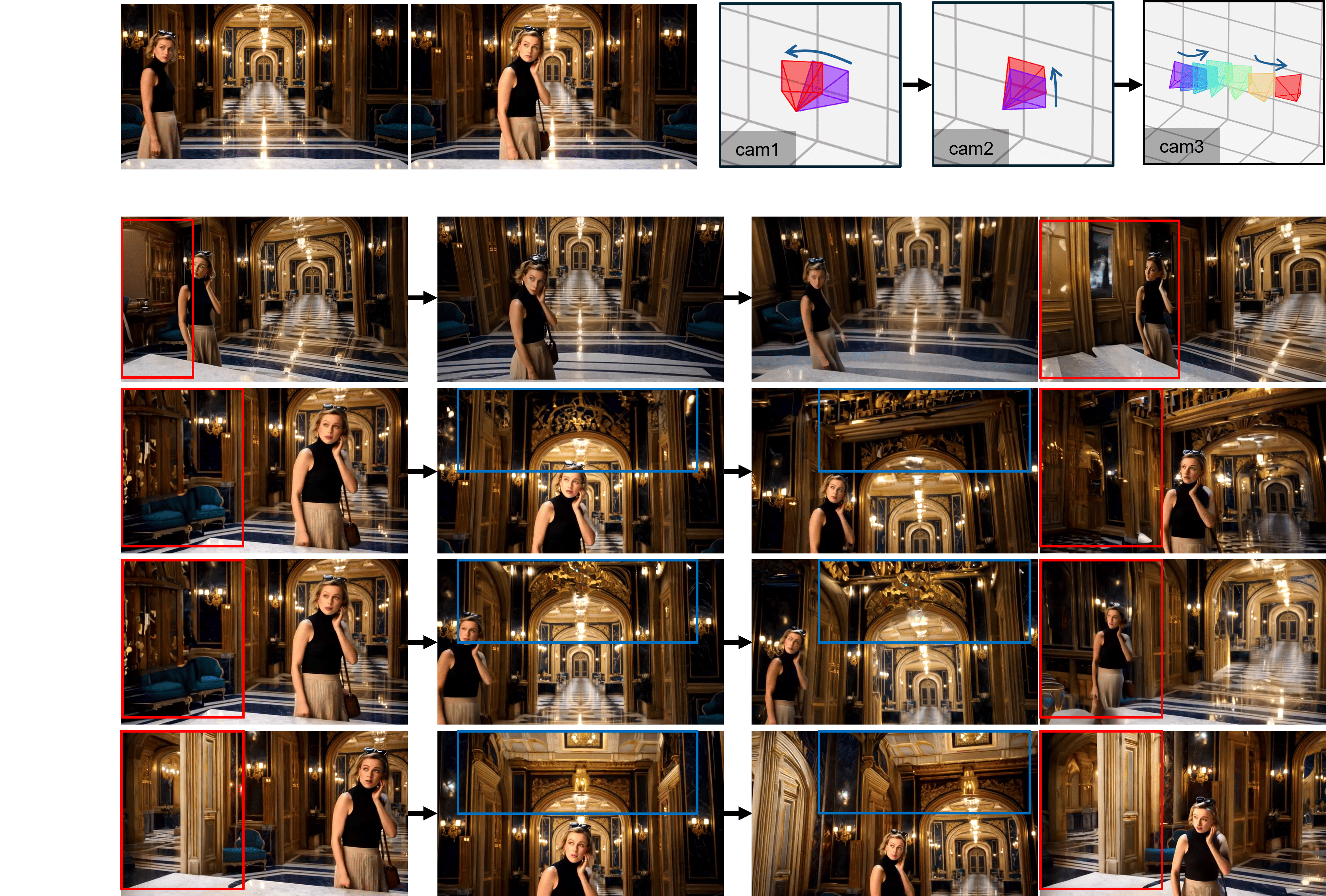

(b) Text-guided Long Video Editing
Input video
TokenFlow
RAVE
CCEdit
LucyEdit
LucyEdit w/ FIFO
Memory-V2V (Ours)
Editing Instruction
"Change apple to orange"
Input video
TokenFlow
RAVE
CCEdit
LucyEdit
LucyEdit w/ FIFO
Memory-V2V (Ours)
Editing Instruction
"Add a beautiful hat to a woman"